DaemonSet dans Kubernetes : Automatisation et Gestion des Noeuds
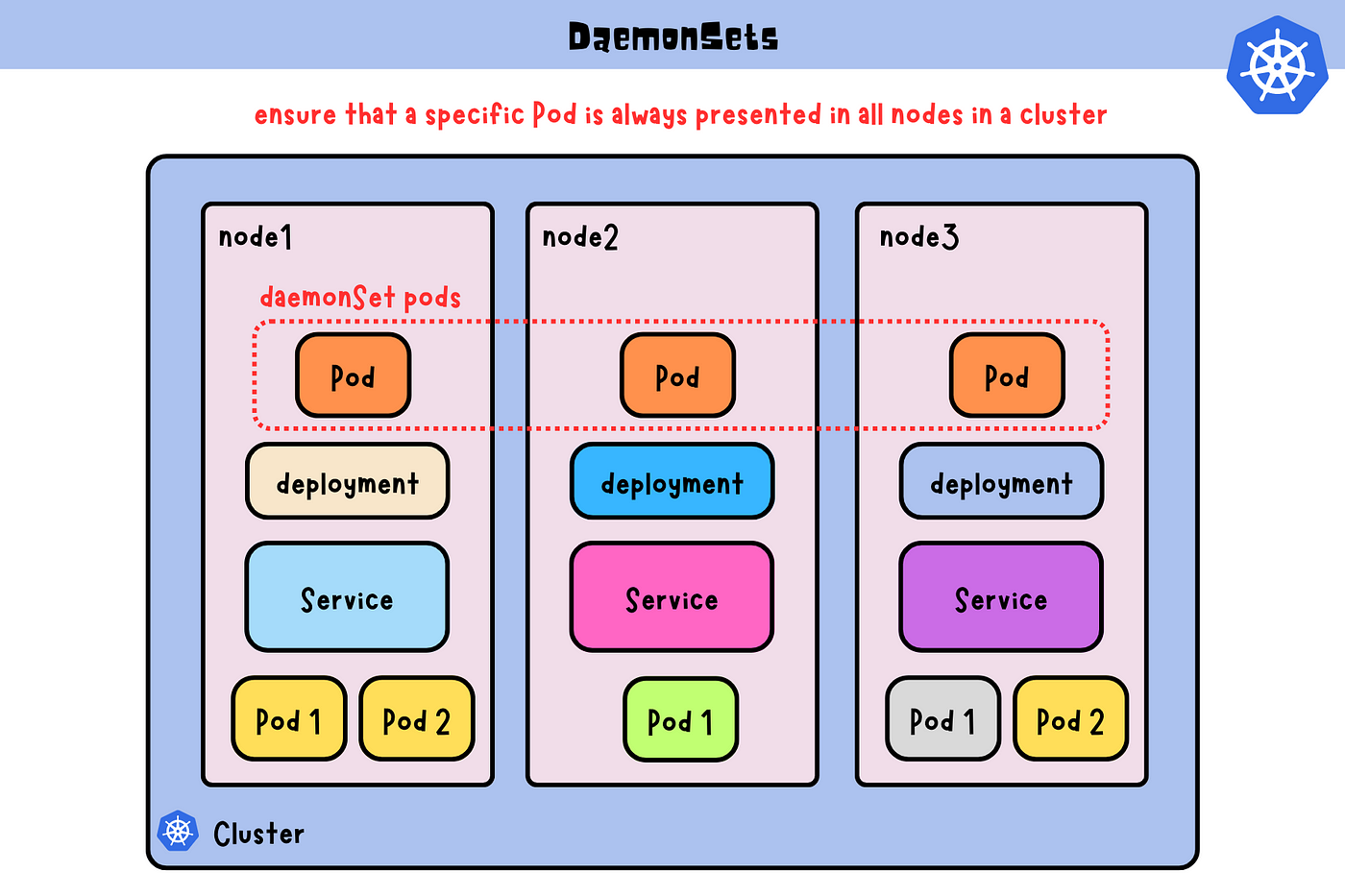
Les DaemonSets : Le Travailleur de l'Ombre de Kubernetes
Les DaemonSets sont les composants que tout le monde utilise sans forcément le savoir. Sur chaque cluster Kubernetes que je gère, il y en a au minimum 3 ou 4 qui tournent. Ce sont les fondations invisibles qui assurent le monitoring, la collecte de logs, et la gestion réseau sur chaque noeud.
Comment Je Les Utilise en Production
Collecte de Logs avec Promtail/Alloy
Sur tous mes clusters, un DaemonSet Promtail (ou Grafana Alloy, son successeur) tourne sur chaque noeud pour collecter les logs des containers et les envoyer vers Loki. Le DaemonSet monte le répertoire /var/log/pods du noeud et lit les fichiers de logs de chaque container.
Chez un client dans les médias, ce DaemonSet collectait environ 50 Go de logs par jour sur un cluster de 8 noeuds. Sans DaemonSet, il faudrait configurer un sidecar sur chaque pod applicatif, ce qui serait un cauchemar de maintenance.
Monitoring des Noeuds avec Node Exporter
Le Prometheus Node Exporter est déployé en DaemonSet pour exposer les métriques système de chaque noeud : CPU, mémoire, disque, réseau. Ces métriques alimentent les dashboards Grafana et les alertes.
Un cas concret : chez un client, une alerte Node Exporter a détecté qu'un noeud avait son disque rempli à 95%. Le DaemonSet Promtail sur ce noeud ne pouvait plus écrire son buffer temporaire. Sans le monitoring par DaemonSet, le problème serait passé inaperçu jusqu'à ce que des pods crashent.
Plugin Réseau (CNI)
Le plugin réseau (AWS VPC CNI, Calico, Cilium) est lui aussi déployé en DaemonSet. C'est lui qui gère l'attribution des IPs aux pods et le routage réseau. Sur EKS, le aws-node DaemonSet est critique : s'il crashe sur un noeud, plus aucun pod ne peut démarrer dessus.
Les Bonnes Pratiques
Priorité et Tolérations
Les DaemonSets d'infrastructure doivent avoir une priorityClassName: system-node-critical pour ne jamais être evictés au profit d'autres pods. Ils doivent aussi avoir des tolérrations sur les taints courantes pour tourner sur tous les noeuds, y compris les noeuds master ou les noeuds taintés pour des workloads spécifiques.
Chez un client dans la Défense, j'ai vu des noeuds GPU taintés qui n'avaient pas de DaemonSet de monitoring à cause de tolérrations manquantes. Ces noeuds étaient des angles morts en termes d'observabilité.
Limites de Ressources
Les DaemonSets consomment des ressources sur chaque noeud. Avec 5 DaemonSets qui prennent chacun 200 Mo de RAM, c'est 1 Go par noeud réservé à l'infrastructure. Sur des petites instances, ça peut représenter 10-15% de la mémoire disponible. Il faut en tenir compte dans le capacity planning.
Mises à Jour Rolling
Les DaemonSets supportent les rolling updates. La stratégie par défaut (RollingUpdate avec maxUnavailable: 1) met à jour les pods noeud par noeud. C'est important pour les DaemonSets réseau : une mise à jour trop agressive du CNI peut couper le réseau de tout le cluster.
DaemonSets et EKS Fargate
Un piège que j'ai rencontré chez un client : EKS Fargate ne supporte pas les DaemonSets. Sur Fargate, chaque pod tourne dans sa propre micro-VM, et le concept de "noeud partagé" n'existe pas. La solution : utiliser des sidecars pour le logging et le monitoring, ou garder un node group EC2 minimal pour les DaemonSets tout en utilisant Fargate pour les workloads applicatifs.
Les DaemonSets sont un outil puissant mais souvent sous-estimé. Bien configurés, ils assurent silencieusement la santé et la visibilité de votre cluster.